Let’s say we have developed a meditation exercise aimed at helping adult Type II (non-insulin dependent) diabetics cope with stress. The idea is that with better management of stress, diabetes will be more effectively managed.
A sample of 20 diabetes patients are given a brief questionnaire to assess stress, then they are randomly assigned to either this new meditation intervention or to a waiting list control group (10 patients in each group). Following the intervention period the stress assessment questionnaire is administered again. The mean change in stress scores from pre- to post-treatment on the questionnaire was -10 (i.e., on average the meditation group experienced a drop of 10 points on the questionnaire relative to baseline following the intervention), whereas the mean change in the control group was -3. So it would appear that my intervention worked. But did it? There are 2 important questions that arise at this point:
- What is the likelihood that the difference observed in a sample represents a true difference in the population from which the sample was drawn? This is a question of statistical significance.
- Is the size of the effect (i.e., the effect size) observed in our sample (in this case, 10 – 3 = 7) a meaningful effect? This is a question of practical significance.
These are both important questions but they are separate questions and it is crucial to remember that. Statistical significance is often mixed up with effect size. People will often be heard saying, “wow that’s a highly significant result so that’s a huge effect!”. It’s often heard but it’s wrong. An effect can be very highly significant yet be a very small effect, and likewise a very large effect can be non-significant. The reason has to do with the sample size. But before getting into this, let’s first look at what statistical significance really means.
Statistical Significance
Our population of interest consists of the entire group of adults with Type II diabetes, of whom in the U.S. alone there are millions. Ideally, we would randomly assign every single one of these folks to either the intervention or control group, and measure pre- and post-intervention stress levels. If a difference was found we would know it was a genuine difference in the population because we performed our test on the population! Thus, if we could run our study on the entire population the first question we asked above would be irrelevant (the second question, regarding whether the effect was big enough to be considered important, would however, still be very relevant). The problem is that running our experiment on the entire population is not practicable and therefore we use a sample drawn from the population. When this is done, the question of statistical significance, or the likelihood that an effect observed in a sample represents a genuine effect in the population, arises.
So I ran the experiment described above and I found a mean improvement of 10 points in the meditation group and 3 points in the control group, for a difference of 7 points. But it is important to remember that these are the means of the particular sample being tested. If I dipped into the population and selected another 20 participants and randomly assigned them to either group and ran the experiment again, I would likely get a slightly different result, perhaps 8 and 2 for the treatment and control groups, respectively, for a difference of 4. A third replication might yield a difference of 6 points. This makes sense. After all, each time the experiment is run, there is a different group of people and it is reasonable to expect that there will be some differences among one group of 20 randomly selected 20 people compared to another group of 20 randomly selected people. Now, say I re-ran the study a 100 times, obtaining a difference score between groups each time. I would then have a distribution of mean differences. This distribution is called the sampling distribution of the mean differences, and its standard deviation called the standard error of the difference between means. The standard errors can then be used to calculate the exact probability of obtaining a particular sample mean (or other statistic) from a given sample size using a known or hypothesized population parameter.
The formulas for standard error are:
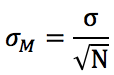
where is the standard deviation of the population

where is the standard deviation of the sample (the estimate of the population parameter)
So the crucial question is this: what is the likelihood that I would obtain a mean difference of 2 in a sample of 20 patients by chance alone? In other words, is the difference between means of observed in our two groups (intervention and control) large when viewed relative to the average expected between any two samples of a specific size drawn randomly from a given population?
Put yet another way, given the amount of spread in the distribution of differences between groups among all samples (standard error of the differences) how far out from the mean would a difference obtained in an experiment need to be before it could be considered far enough to have occurred very unlikely by chance?
In order to answer this question, we would need to compare our results against a distribution with known probabilities. Luckily t-distributions have been worked out for a large number of sample sizes. The first step is to calculate the t-value for our observed difference.
![]()
More formally, the equation for observed t is:

The denominator is the standard error of the difference between the means. In our example, it would be the average difference we would expect to find between any two samples of 20 diabetes patients selected randomly from the population of diabetes patients.
Say our standard error of the difference between means is .65, then we could calculate t as:

Now, the t-value in hand, the only question that remains is what is the probabiliy of obtaining a t value of this magnitude by chance given a particular sample size. To do this we can consult a table with such probabilties but before we do we need the degrees of freedom. In independent samples design,
df = n1 + n2 – 2.
So in our case df = 10 + 10 – 2 = 18.
Consulting a table of t-distributions I find that with df = 18, a t value of 2.10 would be required to reject the null hypothesis for a two-tailed test. In fact, the probability of obtaining this result by chance is about 20%. By convention, any p level > .05 is considered to be not statistically significant. Therefore we would conclude that difference of 3 observed in my sample does not represent a real difference in the larger population of adults with Type II diabetes.
